
One page can show up under several URLs, and search engines may treat those URLs like separate choices. That’s where a canonical tag helps. When we point search engines to the preferred version, we reduce mixed signals and keep the main page in focus.
This matters most for indexing when we use tracking parameters, filters, pagination, or syndicated content. The good news is that canonical tags are simple once we see what they do, and what they don’t do.
What a canonical tag does in SEO
At its core, canonical tag SEO is about naming the main URL when several URLs show the same, or nearly the same, content. Think of it like picking one home address for all copies of the same flyer. The copies may still exist, but we tell search engines which address matters most.
A canonical tag is a link element in the HTML head of a page. A basic example looks like this: <link rel="canonical" href="https://www.example.com/shoes/">
When the preferred page also points to itself, that’s a self-referential canonical tag. It looks the same: <link rel="canonical" href="https://www.example.com/shoes/"> We usually want that because filters, session IDs, and template quirks can create extra URLs without much warning.
When several URLs compete, links and other ranking signals can split across them. A good canonical tag helps consolidate those ranking signals, like link equity and PageRank, around the version we want indexed and shown most often.
A canonical tag is a strong hint, not a removal tool.
That point matters. Search engines can ignore a canonical tag if other signals disagree. For example, if our internal links keep pointing to a parameter URL, Google may choose that version instead. For a solid outside reference, Moz’s canonicalization guide is useful, and our overview of how search engines handle crawling and indexing helps explain why those signals matter.
Common use cases for canonical tags
Canonical tags help prevent duplicate content most effectively in repeat scenarios, especially on larger sites with lots of URL variations.
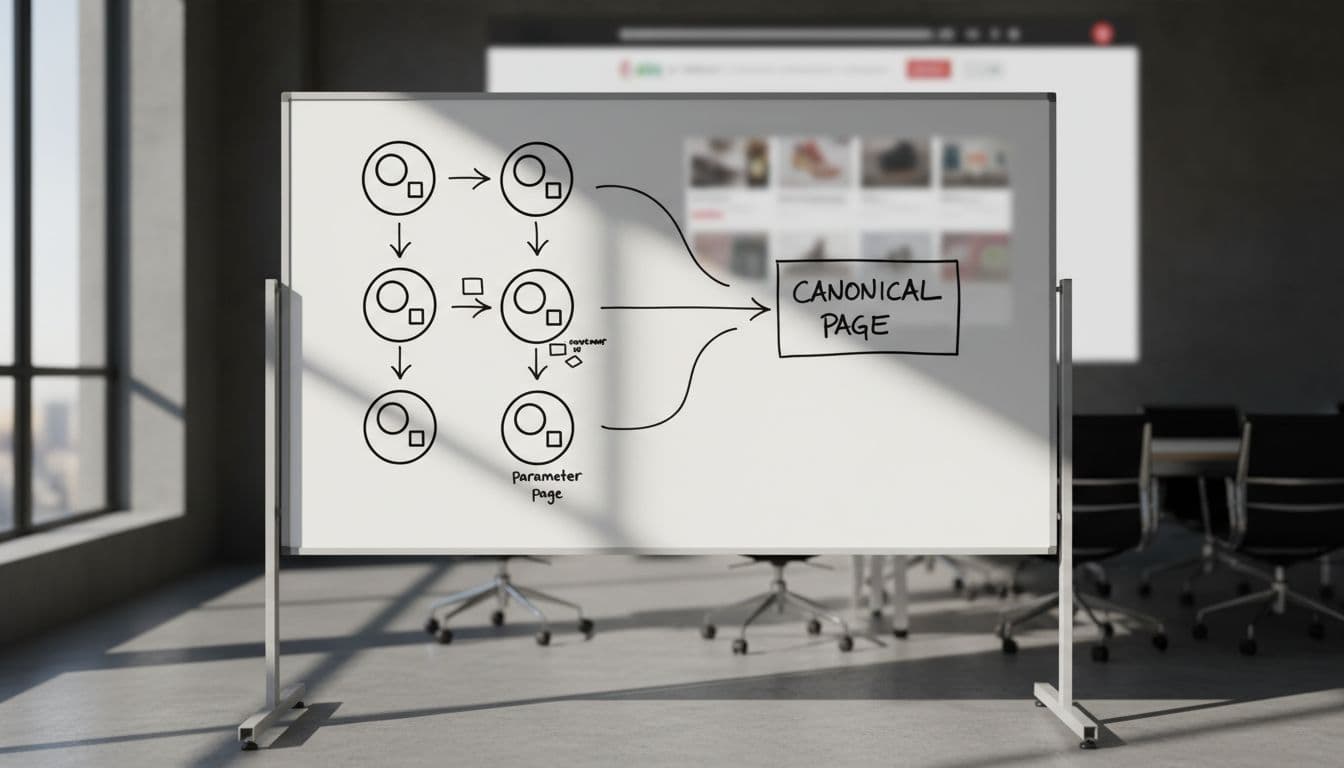
Here’s a quick view of the most common cases:
| Situation | Best move |
|---|---|
| Tracking or sort URL parameters | Canonical to the clean main canonical URL |
| Syndicated article | Cross-domain canonicalization to the authoritative source |
| Paginated category pages | Usually self-canonical each page |
| Low-value filter pages | Canonical or noindex, based on purpose |
URL parameters are the easiest win. If /shoes/?utm_source=email and /shoes/?sort=price show the same core page, both should usually point to /shoes/, the canonical URL (always using absolute URLs). That keeps one clean version as the main destination.
E-commerce filters need more care. A store can create thousands of URLs from color, size, price, and brand combinations. Some filtered pages deserve their own strategy if they match real search demand. Many do not. In those cases, a canonical tag can help consolidate duplicate content signals, while a tighter crawl plan improves crawl budget with canonical tags.
Cross-domain canonicalization helps with syndication. If a partner republishes our article, their page can point back to the authoritative source with something like <link rel="canonical" href="https://www.originalsite.com/guide/">. This works best when the content is very close to the original, and both sites agree on the source page. If the copy changes a lot, search engines may not honor the tag.
Pagination is where many sites slip. We should not canonically point page 2, 3, and 4 of a category to page 1 when those pages contain unique products or posts. In most cases, paginated canonical URLs should self-canonical. Canonicalizing all pages to page 1 can hide useful URLs and weaken internal discovery. Search Engine Land’s guide to canonical URLs gives a good plain-English explanation of that balance.
Best practices for canonical tag SEO in 2026
Effective canonical tag SEO relies on good canonical tags that work best when the whole site agrees with them. That means the rel=”canonical” tag, sitemap, internal links, and redirects should all support the same preferred version. An SEO plugin can automate these canonical tags for efficiency.
- Use one preferred URL format: Keep HTTPS, lowercase URLs, hostname, absolute URLs, and trailing-slash style consistent.
- Implement 301 redirects: Use 301 redirects to consolidate duplicates to the preferred version.
- Point to a 200, indexable page: The target should not be blocked, noindexed, or broken.
- Add self-referencing canonicals: They reduce doubt on pages we want indexed.
- Keep internal links clean: Menus, breadcrumbs, and product links should use the canonical URL.
- Use canonicals for similarity, not for unrelated pages: If pages are too different, search engines may ignore the tag.
- Pair with hreflang for international sites: Use hreflang in conjunction with canonical tags.
If we’re auditing a site template by template, our technical SEO checklist for duplicate URLs is a practical next step to boost sitemap accuracy and indexing efficiency. For more examples, Ahrefs’ canonical tag guide is also helpful.
Troubleshooting common canonical mistakes
When canonicals fail, the problem usually isn’t the canonical tag alone. It’s the conflict around it.
Conflicting canonicals happen when the rel=”canonical” in HTML points to one URL, but a plugin, HTTP header, sitemap, or internal link pattern points elsewhere. Search engines may ignore the hint because the site can’t agree with itself.
Canonicalizing to a non-indexable URL is another common miss. If the target canonical URL is noindexed, blocked in robots.txt, redirected, or returns an error, it’s a poor canonical target. We should point directly to the master copy, the final page that returns 200 and can be indexed.
Canonicals on redirected pages create weak signals too. If page A says page B is canonical, but B uses 301 redirects to C, we’ve created canonical loops and added extra confusion. Point straight to C, then update internal links to match.
Inconsistent internal linking often keeps duplicate content alive. If category cards link to ?sort= versions while canonicals point to the clean canonical URL, search engines get mixed instructions. This is also why canonical tags don’t replace good site structure.
If we want to spot these issues faster, Semrush’s guide to common canonical problems is a handy reference.
Canonical tags won’t make weak pages rank better on their own. Still, they do help search engines focus on the right version when duplicate content shows up.
If we manage a blog, store, or content partnership, now’s a good time to audit a few key templates. Pick one preferred canonical URL pattern, stick to it everywhere, check robots.txt and sitemap for consistency with canonical URL choices, and let the rest of the site follow that lead. This consolidates ranking signals on the master copy to help visibility.





